
AI Blog
AI Technology Transparency: Beyond Black Boxes to Trustworthy AI
AI Technology Transparency: Beyond Black Boxes to Trustworthy AI Discover how AI technology can become

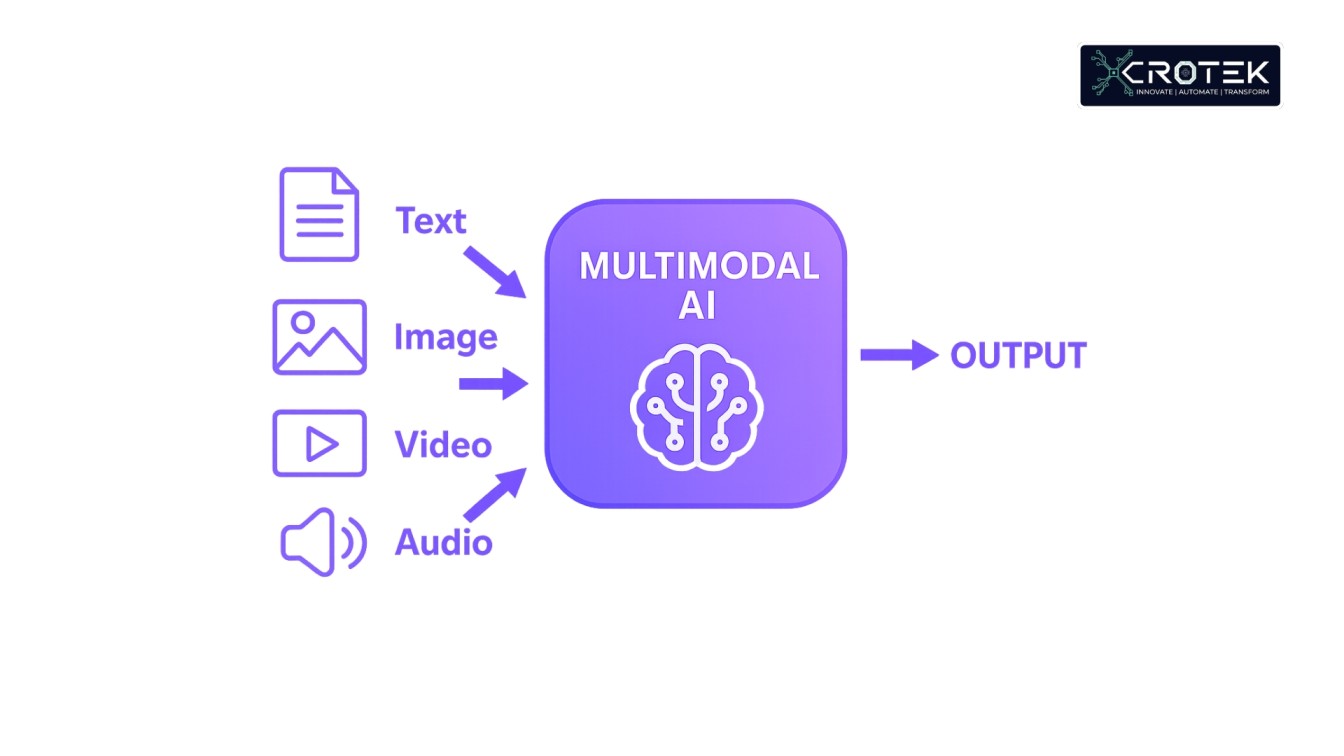
AI Technology Transparency: Beyond Black Boxes to Trustworthy AI Discover how AI technology can become
Gen AI vs Agentic AI: What’s the Real Difference for Businesses? Discover why AI technology

Building Smarter Systems with Agentic AI: A Practical Guide for Enterprises Discover how Agentic AI

Agentic AI: Why Everyone Is Moving Beyond LLMs Agentic AI is the next big leap
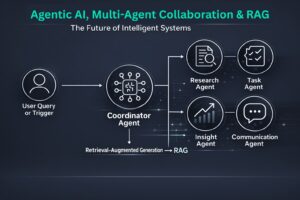
Agentic AI: How Multi-Agent Collaboration and RAG Are Shaping the Future Discover how Agentic Ai,

The Voicebot Shift: How AI is Changing the Way We Talk to Technology in 2025